榆林股票配资 52万张GPU集群塞进一个「盒子」?AI神器破解百模争霸困局

编辑:编辑部 HYZ榆林股票配资
「算力」堪称是AI时代最大的痛。在国外,OpenAI因为微软造GPU集群的速度太慢而算力告急。在国内,企业则面临着「模型算力太多元、产业生态太分散」这一难题。不过,最近新诞生的一款「AI神器」,令人眼前一亮。
如今,快速灵活地获取算力可谓是刚需,就连OpenAI也不例外。
最近,The Information爆料:曾经约定微软是独家云服务器供应商的OpenAI,已经开始找其他家要买算力了。
原因就在于,微软提供算力的速度太慢了!

OpenAI既想要微软提供更先进、算力更强的GPU集群,又要他们加快建设进度。
但微软的计划是,在明年年底之前为OpenAI提供约30万块英伟达GB200。
于是,OpenAI找到了甲骨文,开始洽谈一个预计可在2026年中获得几十万块英伟达AI芯片的数据中心项目。
无独有偶,在算力需求这一块,国内智能算力的年复合增长率预计也将达到33.9%。
但在更进一步的大模型落地上,相比起只缺算力的OpenAI,国内的企业则面临着更多的挑战,比如算力资源管理困难、模型微调复杂等等。
模型算力太多元,产业生态太离散
根据赛迪研究院的数据,2023年我国生成式人工智能企业采用率达15%,市场规模约14.4万亿元。
另一方面据公开数据显示,2023年全年,国内市场对大模型公开招投标的项目只有不到200家,金额5个多亿;而到了2024年,仅上半年的项目就达到了486个,金额13个多亿。
其中,软件的占比在2023年为11%,而2024年上半年却只有5%。相比之下,大模型相关服务则从去年的17%暴涨到今年上半年的30%。也就是说,企业对大模型硬件和服务的需求,基本占了90%以上。
对比可以发现,模型应用和市场趋势之间,存在着巨大的鸿沟。
造成这一现象的原因,首先,就是大模型的幻觉问题。
大模型在预训练阶段所用的知识是通用为主,但在企业的专业领域中,如果还是以算概率来驱动的方式生硬输出,就会答非所问。
第二,要实现大模型与行业场景的深度结合,应用开发流程复杂,应用门槛高。
微调、RAG都要分多个子步骤,应用开发还需要不同专业团队长期协作,研发难度大,耗时也很长。
第三,在不同场景下,不同业务对模型能力有多样需求,比如推理速度快、生成精度高、函数和代码能力强。
由于业务生成环境往往的多模并存,使用的算力资源也是多元并用的。多模和多元的适配问题,常需要软件整个重构,难度大,成本高。
此外,在产业生态上,从芯片到软件框架,再到模型本身,不同厂商的产品数据源不同、技术标准不一,很难统一适配。

在本地化的大模型应用生成与落地中,这些挑战会更加显著。
如何才能让企业(尤其是传统企业)的大模型应用迅速落地?
这时,业内迫切地需要高效、易用、端到端的软硬一体化解决方案,来支撑大模型行业落地。
如果有这样一种开箱即用的产品,无论是模型本身、应用开发,还是算力问题,都能迎刃而解。
算力即得
针对这些痛点,浪潮信息推出了堪称AI应用开发「超级工作台」的元脑企智EPAI一体机。
从算力、平台,到服务,提供了一站式大模型开发平台。

面向真实场景,平台提供了数据处理工具、模型微调工具、增强知识检索工具、应用开发框架等。
而根据不同模型的能力特点,平台还支持调用多模态算法和多元算力。
最强AI算力平台
为了覆盖不同的需求,一体机共有5种规格——基础版、标准版、创新版、高级版、集群版。

总的来说,元脑企智EPAI一体机具备了卓越的算力性能和极致的弹性架构,可支持延时RDMA网络和高性能并行存储。
它们通过分布式并行加速、混合精度计算、高性能算子技术,提升了模型的训练和推理速度,实现应用高并发高能效处理、业务快速上线的需求。
在训练稳定性方面,元脑企智EPAI一体机专为LLM训练微调优化提供了断点续训能力,为大模型训练保驾护航,优化升级算力池化与分配策略,支持按需弹性扩缩容。
接下来,分别看下五个一体机不同的特点。其中,创新版、高级版和集群版均能同时支持训练和推理。
面向模型推理的基础版配备了8块4090D GPU,性价比最高
标准版则搭载了基于Hopper架构的HGX模块化AI超算平台,8颗GPU通过NVlink高效互联
创新版可以为多元算力提供深度适配
高级版专为那些对算力有极高需求的客户而定制,并且提供了训推全流程自动化开发测试工具链
集群版,顾名思义就是机柜级的训推一体机——为那些业务规模较大,有分期建设、按需扩展需求的企业所定制的最高配
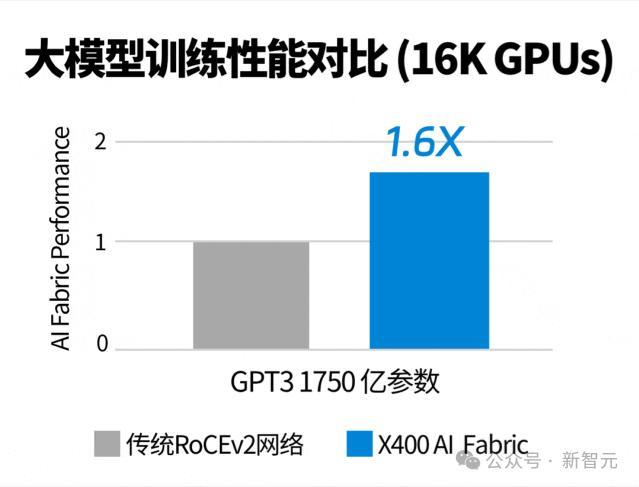
值得一提的是,在网络单元上,集群版配备了浪潮信息自研的「大模型专用交换机」——超级AI以太网交换机X400。
它最高能够扩展到524,288张GPU的超大规模AI算力系统,而且凭借AR自适应路由、端到端拥塞控制、亚毫秒级故障自愈等技术,性能提升至传统RoCE网络的1.6倍。
由此,大型集群实现了超高吞吐量、高可扩展性和超高可靠性。在LLM训练性能提升同时,也大幅缩短训练时长、降低训练成本。
除了硬件上的创新之外,所有的一体机也全部预置了元脑企智(EPAI)大模型开发平台。
这种软硬一体化交付,正是浪潮信息一体机最大优势所在。
开箱即用
有了元脑企智EPAI,浪潮信息的一体机才能为企业客户们,提供开箱即用的能力。
更具体地讲,元脑企智EPAI是专为企业AI大模型应用,高效、易用、安全落地而打造的端到端开发平台。
从数据准备、模型训练、知识检索、应用框架等工具全面涉及,而且还支持调度多元算力和多元模型。
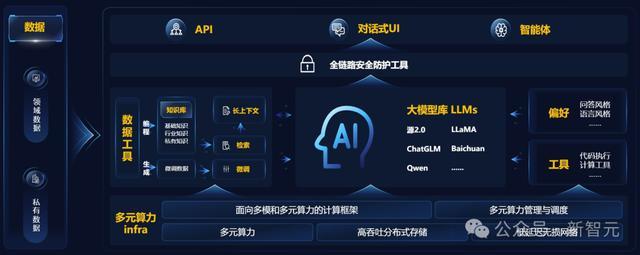
元脑企智EPAI的完整架构
多元多模
首先,元脑企智EPAI平台最核心的一部分是,平台底座能够适配多元多模的基础设施。
多元多模计算框架TensorGlue
多模是指,支持多种模型和多种计算框架。
其中,预置了Yuan2.0、Baichuan2、ChatGLM3、Qwen1.5、GLM4、Llama3等7个基础大模型,以及应用DEMO样例。
还有10+计算框架(MegtronLM、DeepSpeed、Pytorch、Transformer、Llamafactory、Fastchat等),以及多种微调能力,如监督微调、直接偏好优化、人类反馈强化学习等。
同时,它还能广泛支持主流基础大模型结构,支持与用户自研模型的灵活适配和对接。
多元算力管理调度AIStation
而AIStation的作用在于,能够对支持超数千节点的AI服务器。
它可以进行异构算力集群的统一池化管理,通过自适应系统将训练底层的计算、存储、网络环境实现自动化配置。

从开发、训练、微调,再到应用部署,EPAI能够实现全生命周期监管和异常全自动化处理。
而且针对不同业务场景,设备故障自动容错,保证业务时长高效、稳定运行。

简单易用
一体机的简单易用,便体现在了数据准备/生成、微调训练、推理部署中,全部实现自动化。
从企业大模型开发部署业务流程来看,具备通用知识的LLM,就像刚毕业的大学生一样,需要学习企业知识。
因此,第一步数据最关键。
高质量数据自动生成
当前互联网训练数据远远不足,尤其是专业化的数据,而AI数据生成恰好能弥补这一弊端。
高质量数据,才是保障AI模型应用效果的第一要素。
那么企业如何在种类多样、规模庞大数据库中,生成微调数据,并减少处理成本?又该如何将专业化数据为模型所用?
元脑企智EPAI平台通过高质量数据生成,攻破了难题。
企业仅需将原始数据上传,元脑企智EPAI将其提取为文本txt,各种结构化/非结构化文档均可支持。
然后利用大模型生成问题答案对,也就是可以直接微调使用的数据。
最后一步通过「微调数据增强」让AI再自动生成同类型、同主题高质量微调数据。
这一过程,还会对数据抽取后,进行向量编码。
举个栗子,「Apple」会被编码成很长一个向量,其中含了很多丰富的语义信息。它可能代表水果一类,也可能代表苹果公司等等。

全链路微调训练工具
有了数据,接下来就要微调模型了。
好在元脑企智EPAI平台对LLM微调时所需的环境、框架、配置代码等一系列流程,完成了封装。
开发者无需动手写代码,就能微调出领域大模型。
从数据导入、训练参数配置、资源类型配置等均由平台自动管理,大幅提升微调任务的效率。

训练微调完成后,模型部署和上线也是由元脑企智EPAI接手,还提供了多种评估的方式。

总之,高效的数据处理工具,支持微调数据自动生成和扩展,为模型微调训练提供丰富数据源;丰富、完整的模型训练工具,支持SFT优化方式,训练之后支持一键部署。
此外,元脑企智EPAI还支持API、对话式UI、智能体三类使用方式。
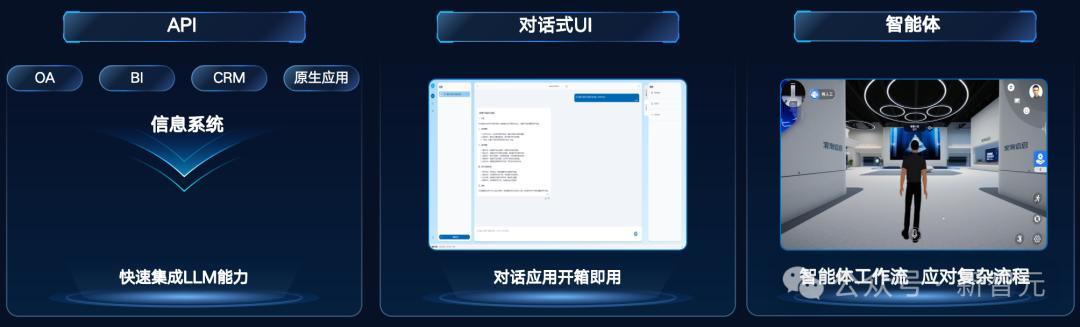
如下是对话式UI界面的样子。
支持RAG,弥补LLM知识无法及时更新难题
另外,还需考虑的一个问题是,LLM幻觉之所产生,是因为无法及时获取到新知识。
而元脑企智EPAI集成了浪潮信息自研的RAG系统,帮助大模型提升了应用效果。
仅需上传一个原始文档,就可以让LLM基于文档内容,进行精准问答和信息检索,快速构建出领域问答能力。
同时,它还预置了一亿条的基础知识库,能够实现端到端30%召回率。

在话式UI界面中,知识库管理中可以上传企业、行业、基础三大类知识。
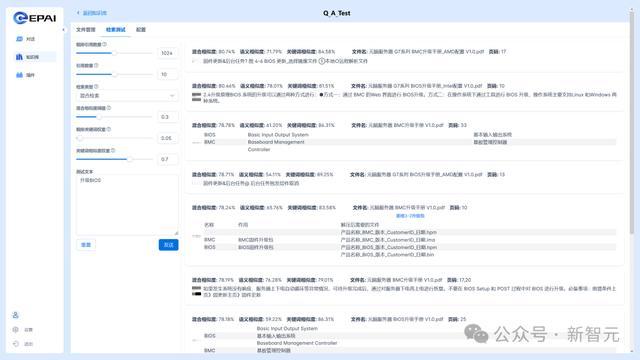
它还支持检索溯源、混合检索、结果重排,由此可以提升端到端检索精度。
数据安全,隐私保护
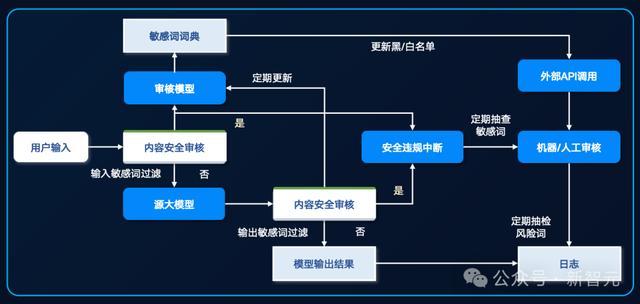
一体机另一个优势在于, 能够保护企业的私有数据不出域,杜绝数据风险。
内置的元脑企智EPAI平台,可以提供全链路的防护,从文件级数据加密、访问控制,到数据存储、备份恢复。
它可以精准控制每个用户数据、模型、知识库、服务的权限,保障多场景使用安全。

还有内容多级过滤和审核体系,对用户输入、模型输出进行快速、准确审核,保障生成内容的安全性与隐私性。
AI应用,每个企业皆可开发
正是因为有以上种种优势,元脑企智EPAI能广泛地赋能企业内部的各类应用场景。
比如研发的代码生成、部门助理,生产的故障识别、维修方案生成,销售的智能客服、文案协作,行政的招聘助手,公文写作等。
开发速度快到低至1周,培训周期短到最快3天。
在浪潮信息内部,元脑企智EPAI就已经大大加快了大家的工作流。
以前如果有数百万行私有代码,注释少,可读性差,需要参考几十页上下文的PDF,专业工程师单个函数开发就需要3周。
但现在浪潮信息利用智能编程助手,可以直接把开发周期缩短至2天。
它能对数十万行代码自动解析,由AI自动生成超过65%的计算框架代码,为研发工程师每天节省了近3个小时的代码。
而基于元脑企智EPAI打造的智能客服大脑「源小服」,涵盖了10+年的产品资料和5000+复杂场景,直接学习了2万余份产品文档、用户手册,百万余条对话等材料。
对于常见技术问题的解决率达到了80%,整体服务效率提升了160%,斩获了《哈佛商业评论》「鼎革奖」的年度新技术突破奖。
百模争霸,不再卡在落地
因为具有以上优势,元脑企智EPAI一体机就为用户解决了燃眉之急。
其中一类重要客户,就是传统制造业客户。
尤其是大型制造业客户,无论是CIO、团队,还是三产公司,在数据、人员、技术方面都有很多积累,而应用本身也有应用牵引的趋势。
而另一类,就是传统的ISV(独立软件开发商)客户。
对于他们,浪潮信息有上百号博士团队在做算力、算法、框架的应用开发工作,在算力上也很强,优势明显。
还有一些用户,需要有对大模型专门的调优能力。
目前的情况是,对于非常专业的应用领域,国内能卖相关服务不多,花很高的代价,也未必找得到。
原本浪潮信息有这个能力,但没有开放。如今,浪潮信息把经验、服务都集成到了一体机的产品中,正好满足了他们的需求。
在浪潮信息看来,如今大模型落地的最大痛点,不是算法,也不是产品,而是行业的know-how。
如果数据不ready,也很难通过一个工具、一个软件或一台设备去解决。
但这时如果有一个一体机的产品,还能跟懂行业、懂数据但不懂AI的ISV互相赋能,大模型的落地就会变得很容易。
从2021年开始到现在,浪潮信息已成行业里的骨灰级玩家。比如2021年做完源1.0后,22年浪潮信息就已经在用RAG做内部智能客服系统。
如今,凭着对模型本身的know-how,以及模型使用上的know-how,浪潮信息再次赋能自己的合作伙伴,加速企业大模型应用开发榆林股票配资,打通了大模型落地最后一公里的难题。